CI/CD con GitHub Actions, ECR y ECS: de push a producción sin tocar la consola
Tienes tu aplicación contenerizada, el Dockerfile listo, y ya probaste que corre bien en local. El siguiente paso es mandarlo a producción — pero no quieres hacer eso a mano cada vez. Quieres hacer git push y que el resto pase solo.
Ese proceso tiene nombre: CI/CD (Continuous Integration / Continuous Delivery). Lo que significa en la práctica: cada vez que haces push a main, un pipeline automatizado construye tu imagen, la publica, y despliega la nueva versión en tu infraestructura. Podría haber un post entero sobre los conceptos de CI/CD, pero hoy el objetivo es concreto — que funcione.
Para esto vamos a usar tres piezas:
- ECR (Elastic Container Registry): el repositorio privado donde vivirán tus imágenes Docker en AWS
- ECS (Elastic Container Service): el orquestador que corre tus contenedores
- GitHub Actions: el motor del pipeline
La arquitectura del flujo
Antes de escribir una sola línea de YAML, es útil entender qué va a pasar exactamente cuando hagas push:
git push → GitHub Actions → build imagen Docker
→ push imagen a ECR
→ actualizar Task Definition (nueva revisión)
→ actualizar ECS Service → rolling deploy
El paso que más sorprende es el tercero. Muchos asumen que basta con subir una imagen nueva a ECR y el Service se actualiza solo — no funciona así. ECS trabaja con Task Definitions: un documento que describe qué imagen usar, cuánta CPU/memoria asignar, variables de entorno, puertos, etc. Para desplegar una versión nueva hay que crear una nueva revisión del Task Definition con el nuevo URI de imagen, y luego decirle al Service que use esa revisión.
Repo de ejemplo
Para que no tengas que escribir el Dockerfile, el task-definition.json, la app de prueba y el workflow desde cero, hay un repo template listo para usar:
github.com/krlosaren/krlosaren-cicd-ecr-ecs-aws — click en “Use this template” y obtienes una copia limpia en tu cuenta.
Adentro hay una app Express (Node.js, port 3000) con un toggle V1/V2 perfecto para visualizar el rolling deploy en acción: cuando mergeas el PR que cambia de V1 a V2, puedes refrescar la URL y ver cómo se alternan las dos versiones hasta que ECS estabiliza en V2. El README del repo tiene el flujo paso a paso.
Pre-requisitos
Para seguir el post necesitas:
- Una cuenta AWS con permisos para crear recursos en ECR, ECS e IAM
- AWS CLI instalado y configurado con
aws configure— si nunca lo hiciste, la guía oficial de AWS CLI te lleva paso a paso - Un repositorio ECR creado (
aws ecr create-repository --repository-name mi-app) - Tu aplicación con un
Dockerfileque ya construya correctamente en local - Tu repo en GitHub
Si todavía no tienes el cluster ECS, service y task definition, no te preocupes — la siguiente sección es justo eso.
Bootstrap mínimo (si aún no tienes ECS)
Si todavía no tienes el cluster, service y task definition creados, este es el camino más corto. Vamos a levantar un service corriendo nginx:latest como placeholder — el pipeline después lo reemplaza con tu imagen real.
1. Setup de red — encuentra tu VPC default y elige una subnet pública:
DEFAULT_VPC=$(aws ec2 describe-vpcs \
--filters Name=is-default,Values=true \
--query 'Vpcs[0].VpcId' --output text)
# Lista las subnets públicas (las que asignan IP pública por default)
aws ec2 describe-subnets \
--filters "Name=vpc-id,Values=$DEFAULT_VPC" "Name=map-public-ip-on-launch,Values=true" \
--query 'Subnets[*].[SubnetId,AvailabilityZone]' \
--output table
Anota uno de los subnet-... y guárdalo en una variable. Después crea el security group con los puertos abiertos:
SUBNET_ID=subnet-xxxxxxxx # reemplaza con uno de los listados arriba
SG_ID=$(aws ec2 create-security-group \
--group-name mi-app-sg \
--description "SG para mi-app" \
--vpc-id $DEFAULT_VPC \
--query 'GroupId' --output text)
# Puerto 80 — para verificar el placeholder de nginx en este bootstrap
aws ec2 authorize-security-group-ingress \
--group-id $SG_ID --protocol tcp --port 80 --cidr 0.0.0.0/0
# Puerto 3000 — donde correrá tu app real cuando el pipeline la deploye
aws ec2 authorize-security-group-ingress \
--group-id $SG_ID --protocol tcp --port 3000 --cidr 0.0.0.0/0
echo "Subnet: $SUBNET_ID / SG: $SG_ID"
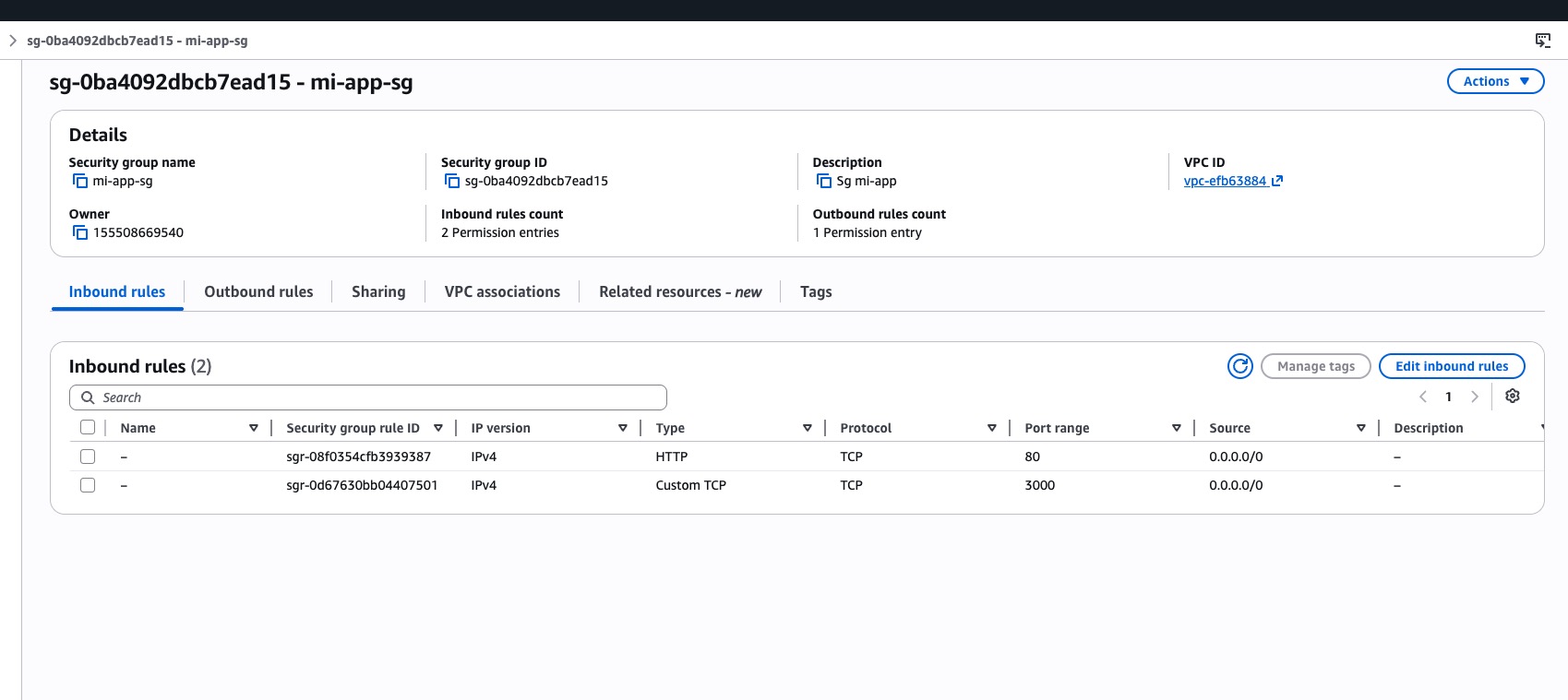 Las dos reglas inbound del SG después de los comandos: HTTP en 80 y Custom TCP en 3000, ambas desde
Las dos reglas inbound del SG después de los comandos: HTTP en 80 y Custom TCP en 3000, ambas desde 0.0.0.0/0.
Abrir
0.0.0.0/0está bien para un setup personal de prueba. En producción acota el CIDR a tu IP o a un load balancer.
2. Task Execution Role — el role que ECS usa para tirar imágenes de ECR y mandar logs a CloudWatch. Si nunca usaste ECS no existe todavía:
cat > trust-policy.json <<'EOF'
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"Service": "ecs-tasks.amazonaws.com"},
"Action": "sts:AssumeRole"
}]
}
EOF
aws iam create-role \
--role-name ecsTaskExecutionRole \
--assume-role-policy-document file://trust-policy.json
aws iam attach-role-policy \
--role-name ecsTaskExecutionRole \
--policy-arn arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy
Si ya existe (porque usaste ECS antes), create-role te tira EntityAlreadyExists — sáltate este paso.
3. Task Definition — guárdalo como task-definition.json (reemplaza <ACCOUNT_ID> con el ID de tu cuenta AWS):
{
"family": "mi-app",
"networkMode": "awsvpc",
"requiresCompatibilities": ["FARGATE"],
"cpu": "256",
"memory": "512",
"executionRoleArn": "arn:aws:iam::<ACCOUNT_ID>:role/ecsTaskExecutionRole",
"containerDefinitions": [{
"name": "mi-app",
"image": "nginx:latest",
"portMappings": [{"containerPort": 80, "protocol": "tcp"}],
"essential": true
}]
}
4. Cluster + Service — registra el TD y crea la infraestructura usando las variables del paso 1:
aws ecs register-task-definition --cli-input-json file://task-definition.json
aws ecs create-cluster --cluster-name mi-cluster
aws ecs create-service \
--cluster mi-cluster \
--service-name mi-app-service \
--task-definition mi-app \
--desired-count 1 \
--launch-type FARGATE \
--network-configuration "awsvpcConfiguration={subnets=[$SUBNET_ID],securityGroups=[$SG_ID],assignPublicIp=ENABLED}"
5. Verifica que el task está corriendo — espera ~30 segundos y obtén la IP pública:
TASK_ARN=$(aws ecs list-tasks \
--cluster mi-cluster --service-name mi-app-service \
--query 'taskArns[0]' --output text)
ENI_ID=$(aws ecs describe-tasks \
--cluster mi-cluster --tasks $TASK_ARN \
--query 'tasks[0].attachments[0].details[?name==`networkInterfaceId`].value' \
--output text)
PUBLIC_IP=$(aws ec2 describe-network-interfaces \
--network-interface-ids $ENI_ID \
--query 'NetworkInterfaces[0].Association.PublicIp' \
--output text)
echo "http://$PUBLIC_IP"
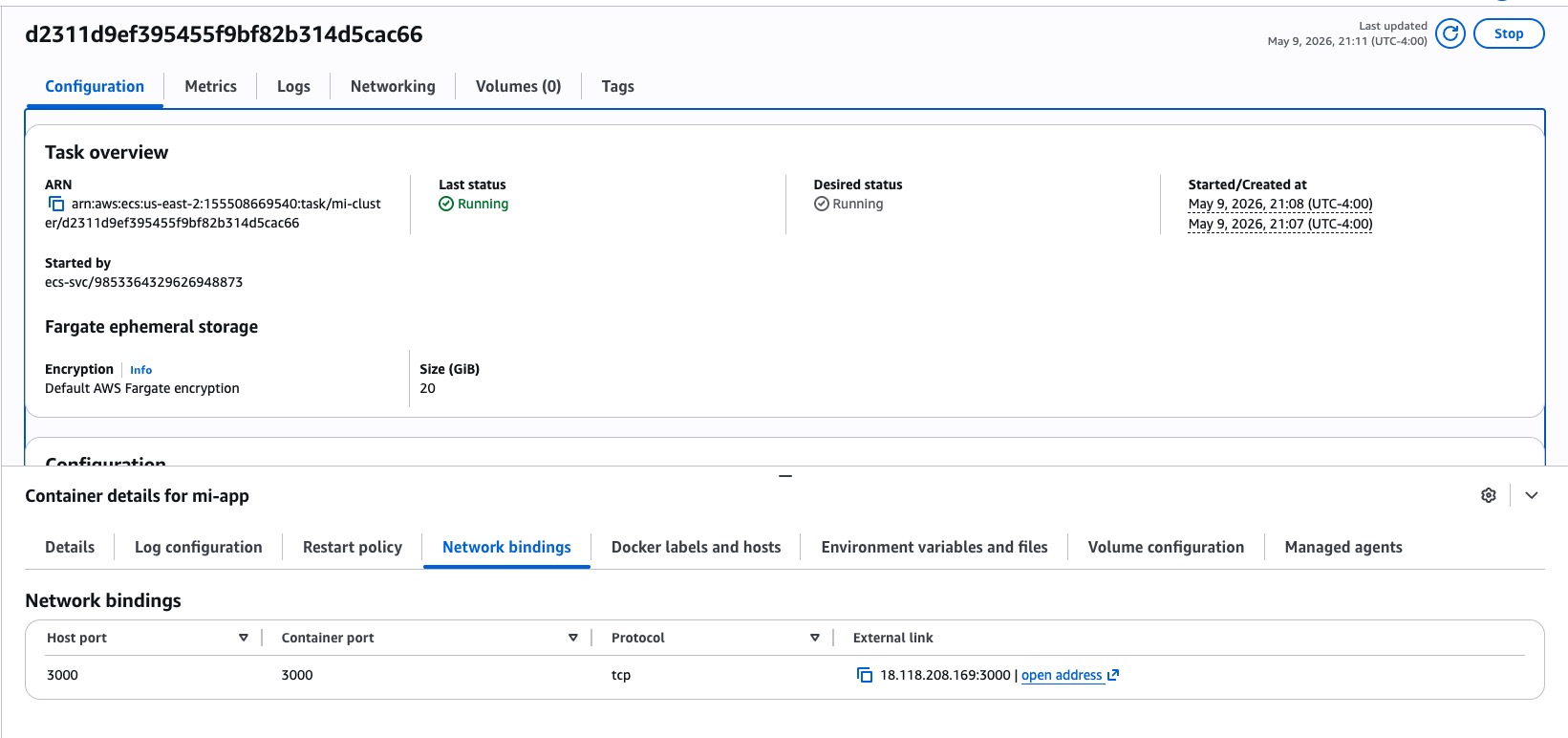 Lo mismo desde la consola: en el detalle del task, la sección “Network bindings” te muestra el container port, el host port y un link directo “open address”. Útil cuando quieres saltarte el CLI.
Lo mismo desde la consola: en el detalle del task, la sección “Network bindings” te muestra el container port, el host port y un link directo “open address”. Útil cuando quieres saltarte el CLI.
Abre esa URL en el navegador — deberías ver el “Welcome to nginx!”. Si lo ves, el cluster, el service y la red están funcionando: el pipeline tiene todo lo que necesita para empezar a desplegar tu app real sobre esa misma infraestructura.
6. IAM User para el pipeline — la policy mínima que necesita:
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:InitiateLayerUpload",
"ecr:UploadLayerPart",
"ecr:CompleteLayerUpload",
"ecr:PutImage",
"ecr:BatchGetImage",
"ecs:DescribeTaskDefinition",
"ecs:RegisterTaskDefinition",
"ecs:DescribeServices",
"ecs:UpdateService",
"iam:PassRole"
],
"Resource": "*"
}]
}
Crea un IAM User dedicado, asígnale esta policy y genera access keys — las usamos en la sección de Secrets más abajo.
En otro post de esta serie veremos cómo construir todo esto desde cero con Terraform (VPC, security groups,
ecsTaskExecutionRole, etc.) sin depender de la consola.
El CI: construir la imagen del contenedor
El workflow vive en .github/workflows/deploy.yml. Para mantenerlo simple dejamos CI y CD en un solo job — todo el flujo en una sola lista de steps:, sin pasar outputs entre jobs. El trigger es un PR que se mergea a main:
name: Build, Push and Deploy <my-app>
on:
pull_request:
branches:
- main
types:
- closed
jobs:
build-and-deploy:
name: Build, Push & Deploy
runs-on: ubuntu-latest
if: github.event.pull_request.merged == true
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v4
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ secrets.AWS_REGION }}
- name: Login to AWS ECR
id: login-ecr
uses: aws-actions/amazon-ecr-login@v2
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Set image tags
id: set-tags
env:
ECR_REGISTRY: ${{ secrets.ECR_REGISTRY }}
ECR_REPOSITORY: ${{ secrets.ECR_REPOSITORY }}
run: |
# Usamos los primeros 7 caracteres del SHA del commit como tag
IMAGE_TAG="${GITHUB_SHA::7}"
TAG="${ECR_REGISTRY}/${ECR_REPOSITORY}:${IMAGE_TAG}"
echo "image=${TAG}" >> $GITHUB_OUTPUT
- name: Build & Push Docker image
id: build-image
uses: docker/build-push-action@v6
with:
push: true
tags: ${{ steps.set-tags.outputs.image }}
Dos detalles que vale la pena destacar:
- El tag con los primeros 7 caracteres del SHA te da trazabilidad 1-a-1 entre imagen y commit. Cuando algo se rompe en producción, el tag te lleva directo al
git show <sha>que la generó — mucho más útil que unlatestopaco. - El guard
if: github.event.pull_request.merged == trueno es opcional. El eventoclosedtambién se dispara cuando alguien cierra un PR sin mergear, y obviamente no queremos deployar en ese caso. Sin eseif, cualquier PR cerrado dispararía un deploy a producción.
El CD: actualizar ECS
Una vez que la imagen nueva está en ECR, el pipeline tiene que:
- Descargar el JSON del Task Definition actual
- Reemplazar el image URI por el nuevo
- Registrar una nueva revisión del Task Definition
- Actualizar el Service para que use esa revisión
Estos steps se agregan al mismo job, justo después del Build & Push Docker image. GitHub Actions tiene una acción oficial para cada paso:
- name: Descargar task definition actual
run: |
aws ecs describe-task-definition \
--task-definition mi-app \
--query taskDefinition > task-definition.json
- name: Actualizar imagen en task definition
id: task-def
uses: aws-actions/amazon-ecs-render-task-definition@v1
with:
task-definition: task-definition.json
container-name: mi-app
image: ${{ steps.set-tags.outputs.image }}
- name: Desplegar en ECS
uses: aws-actions/amazon-ecs-deploy-task-definition@v1
with:
task-definition: ${{ steps.task-def.outputs.task-definition }}
service: mi-app-service
cluster: mi-cluster
wait-for-service-stability: true
Un detalle que cuesta horas si lo confundes: container-name: mi-app debe coincidir con el campo name del container dentro del Task Definition — no con el nombre del service, ni con el family, ni con el repositorio de ECR. Si pones cualquier otro valor obtendrás container 'X' not found in task definition y el deploy falla.
El flag wait-for-service-stability: true hace que el pipeline espere hasta que el rolling deploy termine antes de marcar el job como exitoso. Si el nuevo contenedor falla al iniciar, el pipeline falla — lo que es exactamente lo que quieres.
Secrets en GitHub
Configura estos secrets en Settings → Secrets and variables → Actions:
AWS_ACCESS_KEY_ID— access key del IAM User dedicado al pipelineAWS_SECRET_ACCESS_KEY— su secret correspondienteAWS_REGION— región donde viven tu ECR y tu ECS (ej.us-east-1)ECR_REGISTRY— host del registry (ej.123456789012.dkr.ecr.us-east-1.amazonaws.com)ECR_REPOSITORY— nombre del repositorio dentro de ECR (ej.mi-app)
El IAM User es el que creaste en el bootstrap mínimo, con la policy de ECR + ECS. Importante: crea un user dedicado al pipeline, no reuses tu user personal — facilita auditoría y rotación si las credenciales se filtran.
El resultado
Con esto en su lugar, el flujo completo queda:
- Mergeas un PR a
maindesde la UI de GitHub - GitHub Actions detecta el
pull_request closedconmerged == truey arranca el job - Construye la imagen y la sube a ECR con el tag del commit
- Registra una nueva revisión del Task Definition
- ECS hace rolling deploy — reemplaza los contenedores viejos por los nuevos gradualmente
- El pipeline marca verde cuando el Service estabiliza
Sin abrir la consola. Sin clicks. El pipeline falla ruidosamente si algo sale mal, y no toca producción hasta que la imagen está lista.
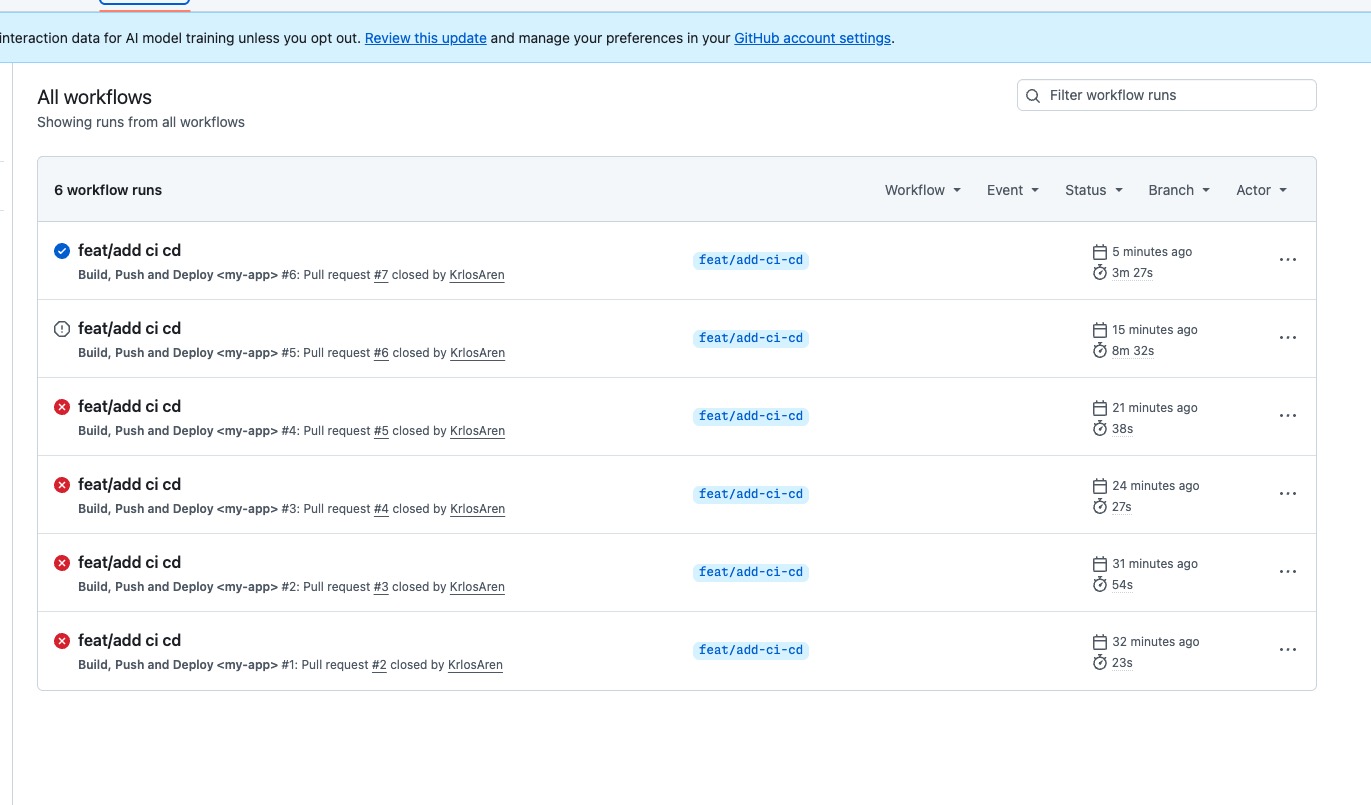 Una sesión típica de armado: los primeros runs fallaron (permisos faltantes, secrets mal cargados, container-name que no matcheaba), hasta que estabilizó en verde. El pipeline ruidoso te dice exactamente qué romper para que el siguiente PR pase.
Una sesión típica de armado: los primeros runs fallaron (permisos faltantes, secrets mal cargados, container-name que no matcheaba), hasta que estabilizó en verde. El pipeline ruidoso te dice exactamente qué romper para que el siguiente PR pase.
¿Y si algo sale mal una vez que ya está en producción? El rollback es una sola línea:
aws ecs update-service \
--cluster mi-cluster \
--service mi-app-service \
--task-definition mi-app:<revisión-anterior>
ECS hace el rolling back con la misma estrategia con la que subió la versión nueva.
Limpiar los recursos
Cuando termines de probar y quieras devolver la cuenta a cero (o al menos dejar de pagar por el service corriendo), este es el orden correcto de borrado. La regla es de afuera hacia adentro: primero apagas los tasks, después el service, después el cluster, y al final los recursos de red.
# 1. Apaga los tasks y elimina el service
aws ecs update-service --cluster mi-cluster --service mi-app-service --desired-count 0
aws ecs delete-service --cluster mi-cluster --service mi-app-service --force
# 2. Elimina el cluster
aws ecs delete-cluster --cluster mi-cluster
# 3. Elimina el security group (sólo se puede borrar cuando ya nadie lo usa)
aws ec2 delete-security-group --group-id $SG_ID
# 4. Elimina el repo de ECR (--force borra también las imágenes adentro)
aws ecr delete-repository --repository-name mi-app --force
# 5. (Opcional) Elimina el ecsTaskExecutionRole si no lo vas a reusar
aws iam detach-role-policy --role-name ecsTaskExecutionRole \
--policy-arn arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy
aws iam delete-role --role-name ecsTaskExecutionRole
# 6. Elimina el IAM User del pipeline
aws iam list-access-keys --user-name pipeline-user
aws iam delete-access-key --user-name pipeline-user --access-key-id <KEY_ID>
aws iam detach-user-policy --user-name pipeline-user --policy-arn <POLICY_ARN>
aws iam delete-user --user-name pipeline-user
El subnet y la VPC default no los toques — son recursos compartidos que AWS te dio al abrir la cuenta. Borrarlos puede dejarte sin red para futuros experimentos.
Próximos pasos
Este pipeline funciona y te tiene en producción rápido, pero las access keys son credenciales de larga vida que rotan mal y son difíciles de auditar. El siguiente paso natural es migrar a OIDC con un IAM Role: el runner asume el role solo durante la corrida del pipeline, sin credenciales guardadas en GitHub. Lo cubrimos en otro post.